In the absence of anything to do other than research my 3rd year project, exercise, and void my wallet in the Steam sales, here is the result of 5 hours work. You can see the whole project on GitHub.
The engine runs off an input consisting of 5-tuples. That is, lines that fit the form…
There is also an optional line (which must be first in the file if it is not to be ignored) which consists of an unbroken string of B’s, 0’s, and 1’s. This line, if found, will set the initial value of the tape.
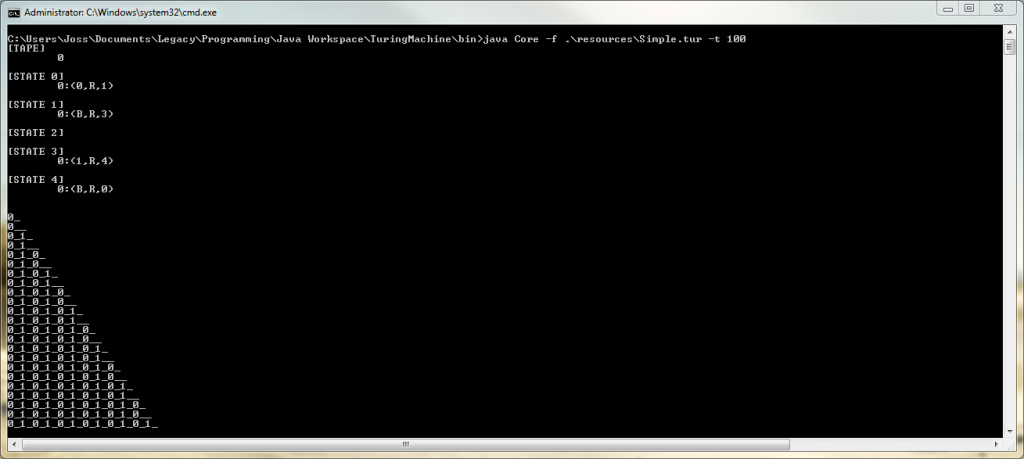
Here is a simple turing machine which generates an infinite string of 0 space 1 space 0 space 1…. Since this program expects a blank tape one isn’t defined.
One really good thing about this little project is having stumbled upon a great little Java Project calls JArgs, which is a Argument Parser for better dealing with Command Line Arguments. God knows why such a system is not built into the JDK in the first place.
This has allowed me to make a really neat way of running the program. You can define a file via the -f flag or pipe a file in via standard input. Thus both java TuringMachine -f .\resources\Simple.tur -t 100 and java TuringMachine < .\resources\Simple.tur -t 100
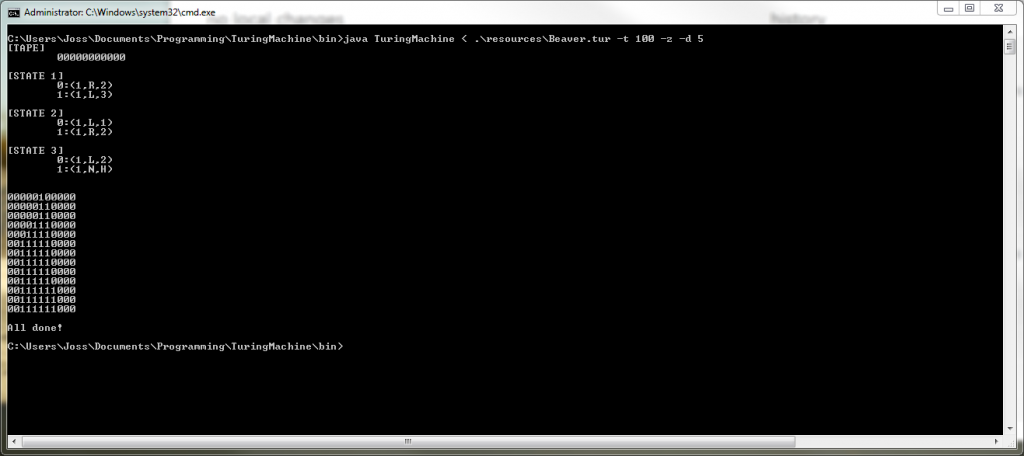
The -z flag is quite important as for some turing machines we need to imagine that the default value for an infinitely long tape is a blank cell, and for some that it is a 0. As an example, the Busy Beaver Turing Machine imagines a 0 filled tape.
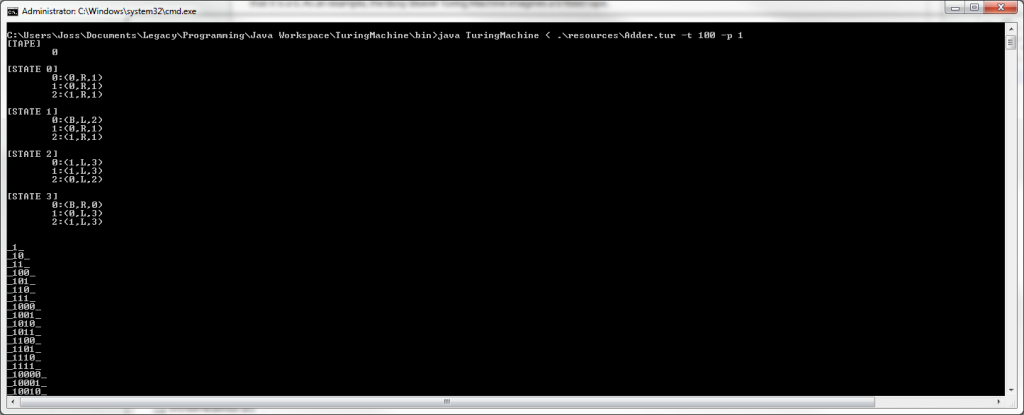
For turing machines where we know the value of the tape is only relevant during a certain state, such as an adder, we can limit tape printing to that state only using the -p flag.
The -q flag stops all but the final output being displayed. This is good for when you know a program will run for a long time and eventually end. However if you do not know whether the Turing Machine will halt it is inadvisable to use this flag.
Finally the -t flag allows you to slow the execution of the Machine down so it is easier to view. It simply puts a thread sleep in after each instruction of the millisecond length given.
Here is an implementation of a 3-State Busy Beaver. This Machine would need to be run with the -z flag set as it assumes a 0 filled tape. Edit, additionally given that the Busy Beaver outputs to the tape both to the left and right of the start position it may be useful to pad the tape with default value on either side of the head. We can do this with the -d flag.
Finally here is a Binary Adder. It counts upwards indefinitely from the value in the initial tape. For a machine like this we would use the -p flag to denote that we only want to print the tape in state 1.
Currently working on a new skin for my desktop and am really happy with the results so far.
For those that don’t know, Rainmeter is a system for displaying Live Generated Content right on your desktop. It can even be configured so that the elements ignore click events and can’t be moved. Effectively bringing your wallpaper to life!
I started by going on /r/Rainmeter for some inspiration and eventually came across a post which used a rotoscope layer to hide text in the image. In the post the Redditor linked this post on Deviant Art.
From the second the page loaded, I was in love.
Personally I think the original guy cluttered his desktop up a bit too much. I found the original wallpaper at full resolution and set about turning his 1680×150 desktop into one that would work on my 1920×1080.
All of this was pretty easy, the only annoying part was making the rotoscope layer for the foreground sand. In the end to get a good enough edge I had to just manually go along the line very accurately tracing it, and finally adding a 2px feather to hide any imperfections and blend it to the wallpaper.
Next came the coding. Rainmeter is written in .ini files. You organise your skin into a base folder, and subfolders for each individual Meter. You can write more than one .ini file into one of those subfolders but Program will only let you turn one of them on at a time. This allows you to build sever alternate versions of the same Meter, so anyone who downloads it can choose their favourite.
Here’s the ini file for the rotoscope layer. It’s the simplest of all the ones in the skin, I just wanted to show you what the code looked like. You can see the code for all the layers in the Gist.
Only thing about this skin that I cannot distribute, sadly, is that I can’t say where or how I got my hands on HelveticaNeue… me hearties. ARRRR!
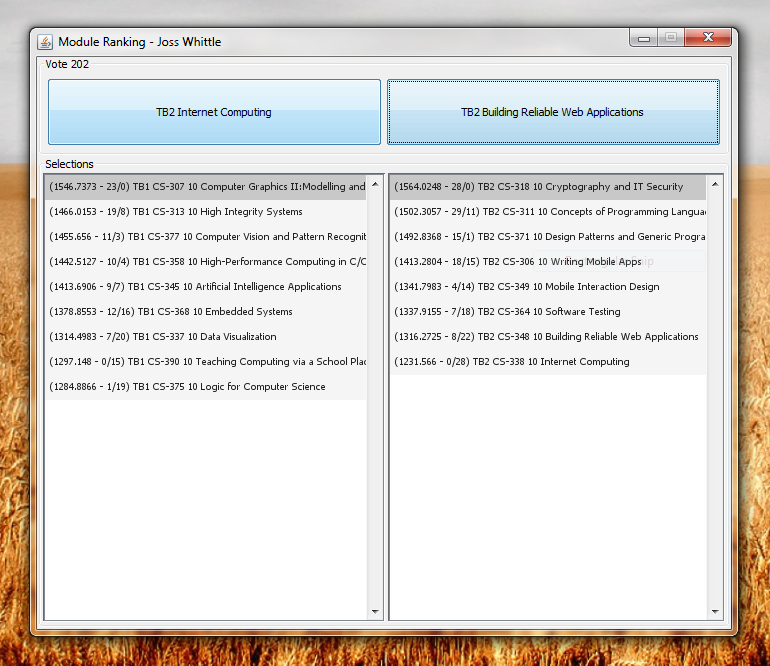
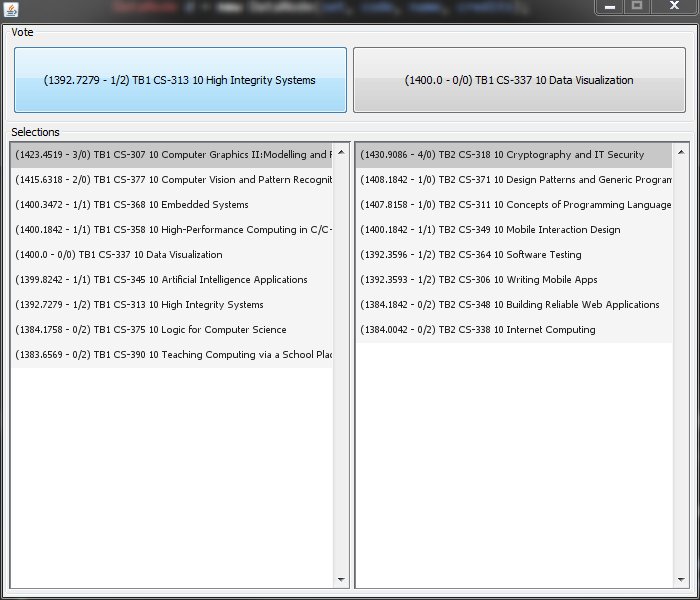
After 201 votes I am pretty happy with the result ranking for which modules I want to take next year.
As it stands there are two mandatory modules, CS-344 and CS-354, which are related to the 3rd year project. Each of those is weighted at 20 credits meaning that I have to fill 80 credits worth of module selection to get 120 credits next year. At 10 credits a pop this means 8 modules.
So here comes the decision do I split it evenly and do four modules in TB1 and four in TB2? Or do I take more modules in TB1 because there is more there that I want to do? See, I said I was indecisive… Now to write a ranking program to let me vote on which of those I want to do… I kid. But seriously this is stressing me out.
…
After a quick conversation with my rather inebriated father (more akin to a conversation with a parrot. Love you Dad) I have decided to split the modules 5/3 and in TB1 do:
CS-307 Computer Graphics II:Modelling and Rendering
CS-313 High Integrity Systems
CS-377 Computer Vision and Pattern Recognition
CS-358 High-Performance Computing in C/C++
CS-345 Artificial Intelligence Applications
And in TB2 do:
CS-318 Cryptography and IT Security
CS-311 Concepts of Computer Programming Languages
CS-371 Design Patterns and Generic Programming
I am slightly worried about the thought of five exams in TB1 but I think I’ll be able cope with it.
Those who know me know that I am one of the most indecisive people in the world. So when posed with the question of what modules to choose next year I was completely at a loss! So much so that I have been putting it off for several months.
But now with the release of our Year 2 course marks and exam results I found myself continually going on and off of the Uni Intranet in order to check my results and show my parents. It occurred to me that with this traffic back and forth passed the button for module selections I really had NO excuse not to do them already.
But what to choose? I couldn’t do it! But then it came to me, two years ago after watching The Social Network I had wanted to try and recreate Zuckerberg’s ‘Facemash’ website so I had made on a subdomain of L2Program ‘Catmash’. A system for voting which of two cats was cuter. A fun little experiment with a powerful ranking algorithm; an algorithm that I already had the code for…
It has taken me about 2 hours to get this little program up and running. Every time it ‘poses a question’ to you it randomly selects Term Block 1 or 2 and then two unique modules within that Term Block. You click on the one you would rather take and over the course of several hundred votes it builds two lists of modules in the order of which you ‘really’ want to take.
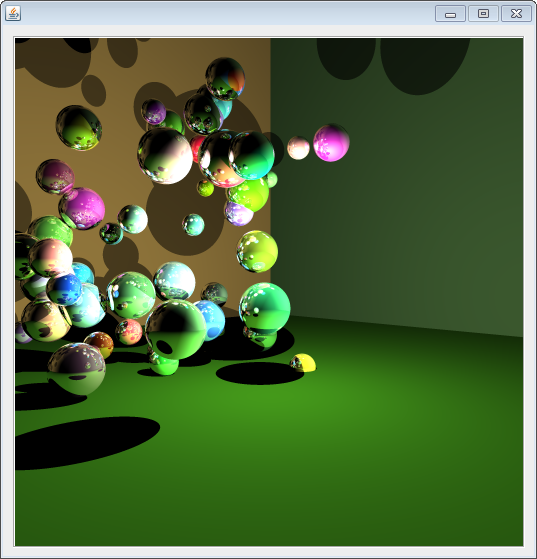
A few months ago, inspired by our Graphics Course, I decided to write a Ray Tracer. I had written one once before, in C# of all things, the summer before starting university. But it was crude and took 3 minutes to render one sphere, incorrectly too… I knew I could do better. Here is the result of 3 days worth of playing around with Java between lectures.
I didn’t quite get triangles working at the time. It was an issue to do with Java’s implementation of floats not having enough precision. My next Ray Tracer will be in C++ so that shouldn’t be a problem. (I know… A bad programmer always blames his tools…)
Thought I’d move some posts over from the L2Program Blog.
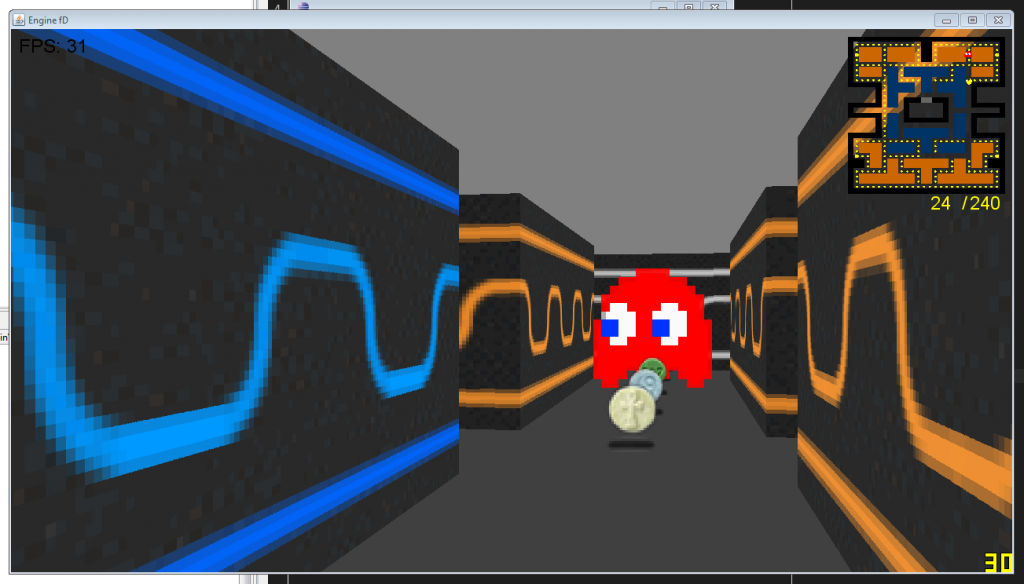
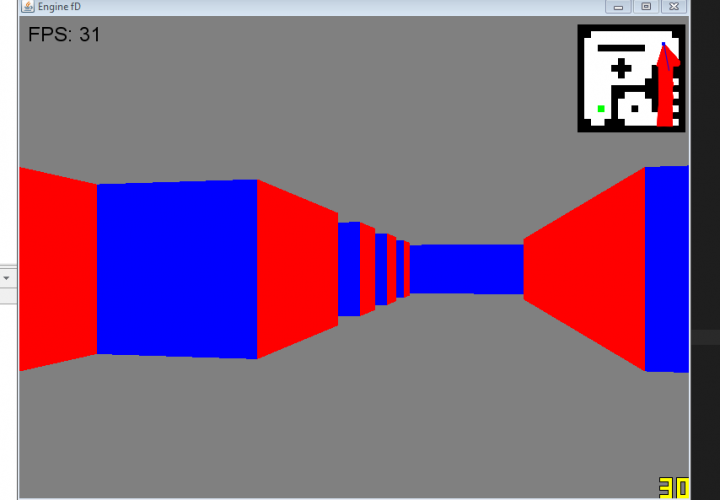
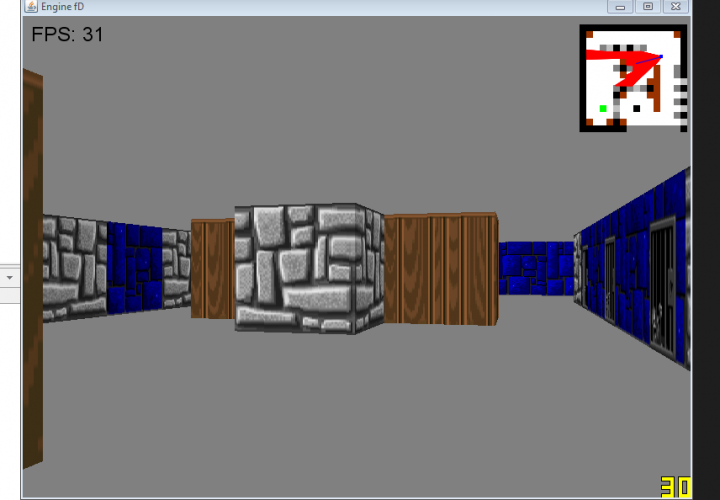
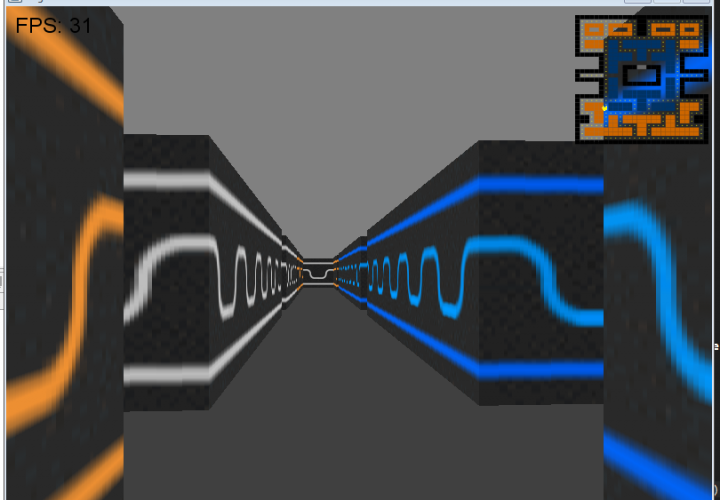
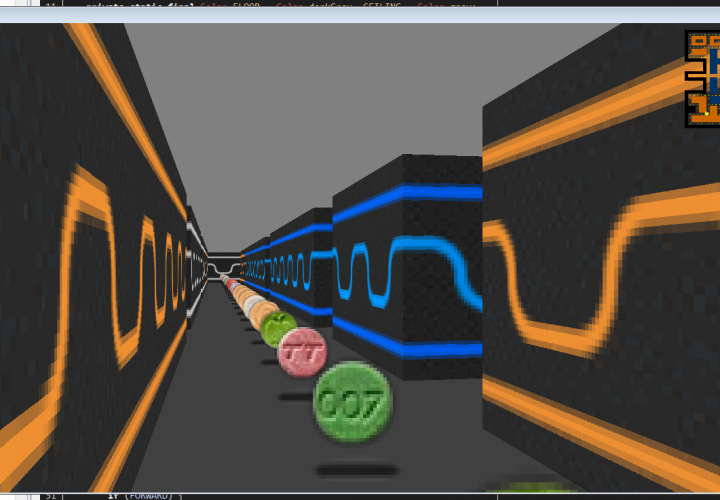
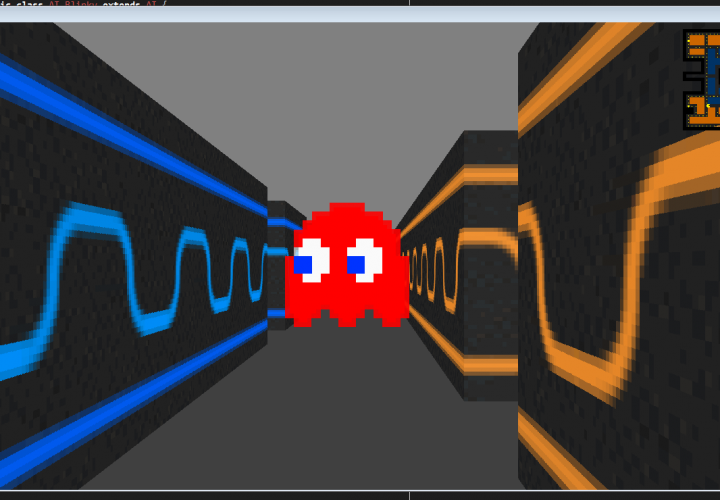
This was my first major project of this summer, the second being this site. The idea was to create a Pseudo-3D rendered game like the classic Wolfenstein3D.
This style of rendering takes a 2D world and “fakes” 3D by making things further away from the camera shorter in the middle of the screen.