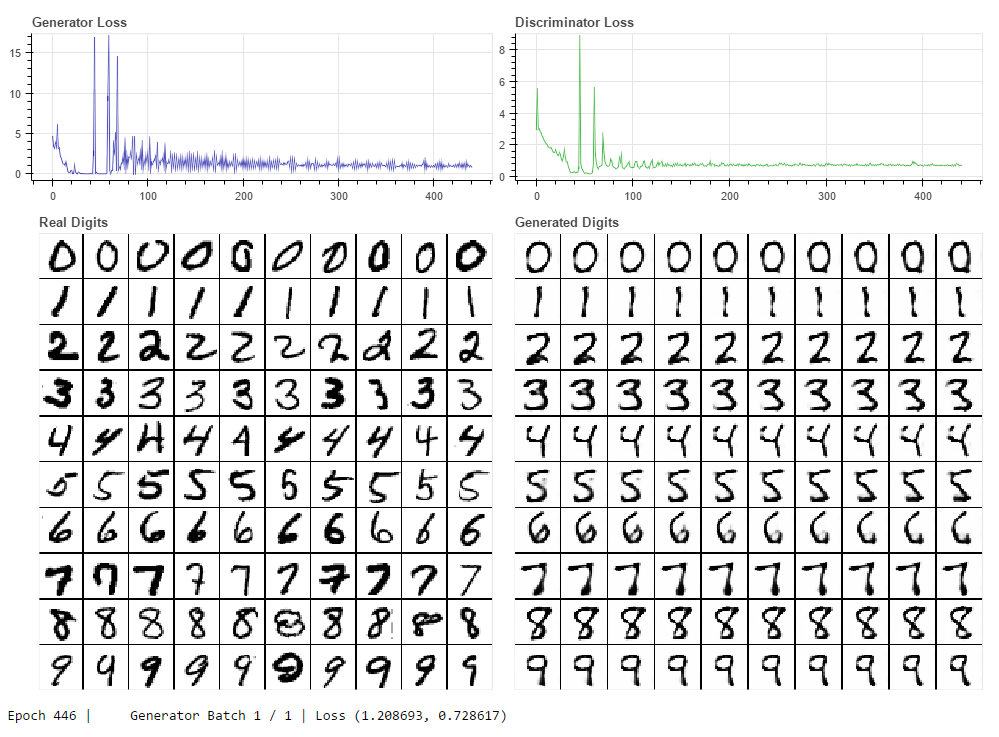
An experiment in augmenting a GAN architecture to use class-labels to guide image synthesis. The generator network takes as input a vector of 1 x 10 random values to use a seed for image synthesis, and a 1 x 10 one-hot vector for the class-label representing the desired digit.
In the above image the generated digits are made by giving the same 1 x 10 random vector for each image, with the y-axis varying the class-label, and the x-axis sweeping the value of one (common to all rows) randomly chosen column in the random vector between [0,1).
It’s still not perfect, far from it in fact, but it’s progress none the less. I’ve been reading a lot lately about Metropolis Light Transport, Manifold Exploration, Multiple Importance Sampling (they do love their M names) and it’s high time I started implementing some of them myself.
So it’s with great sadness that I am retiring my PRT project which began over a year ago, all the way back at the start of my dissertation. PRT is written in Java, for simplicity, and was designed in such a way that as I read new papers about more and more complex rendering techniques I could easily drop in a new class, add a call to the render loop, or even replace the main renderer all together with an alternative algorithm which still called upon the original framework.
I added many features over time from Ray Tracing, Photon Mapping, Phong and Blinn-Phong shading, DOF, Refraction, Glossy Surfaces, Texture Mapping, Spacial Trees, Meshes, Ambient-Occlusion, Area Lighting, Anti-Aliasing, Jitter Sampling, Adaptive Super-Sampling, Parallelization via both multi-threading and using the gpu with OpenCL, Path Tracing, all the way up top Bi-Directional Path Tracing.
But the time has taken it’s toll and too much has been added on top of what began as a very simple ray tracer. It’s time to start anew.
My plans for the new renderer is to build it entirely in C++ with the ability to easily add plugins over time like the original. Working in C++ gives a nice benefit that as time goes by I can choose to dedicate some parts of the code to the GPU via CUDA or OpenCL without too much overhead or hassle. For now though the plan is to rebuild the optimized maths library and get a generic framework for a render in place. Functioning renderers will then be built on top of the framework each implementing different feature sets and algorithms.
I joke. So far it’s just been a lot of reading papers on graphics, most of which I do not understand. :(
Anyway, as a fun little side project I’ve been working on a 3D Ray Caster using my old favourites, OpenCL, OpenGL, and C++. It’s quite similar in concept to the renderer for my dissertation project last year but with a simplified rendering method and faster performance.
The goal for this project is to revisit Voxel Rendering which I played around with over the summer, and possibly to revisit game development with a new version of my Aliens First-Person Pacman game.
Currently the program has seven hardcoded Axis Aligned Bounding Boxes (AABB’s) which it renders as the camera orbits around them. I’m working on a method to organise AABB’s into a flat packed Oct-Tree which can be passed to the GPU. Once this is working it should be trivial to construct an AABB Oct-Tree of the CT Scanned skull I used before, or to construct a simple game.
Another thing I may look into is modifying the Aliens game to have textured floors and ceilings using floor-casting and possibly to have maps with multiple vertical levels.
I’ve been meaning to do it for a while but I have finally gotten around to making a Template for OpenCL & OpenGL Projects in Visual Studio 2012.
The host application is written in C++ using GLew and freeGLUT to interface with OpenGL, and the Amd APP SDK to interface with OpenCL as I am running a ATI 5850 GPU. Building upon the template is fast and easy and really comes down to just a few core functions which differ for each program. Below is a simplified version of the functions each program must implement.
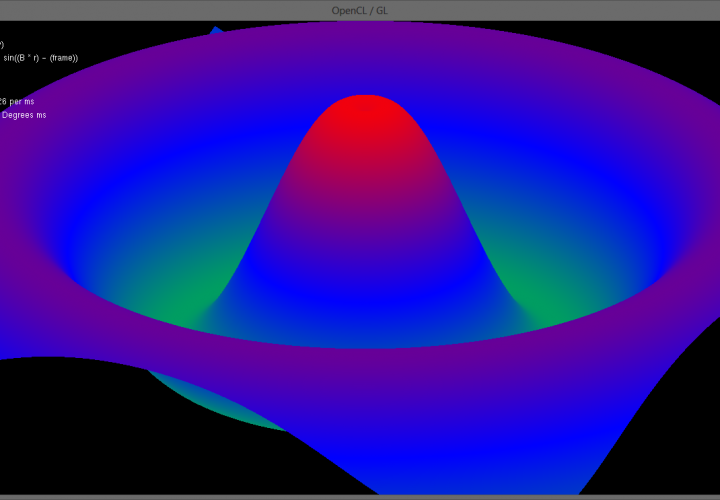
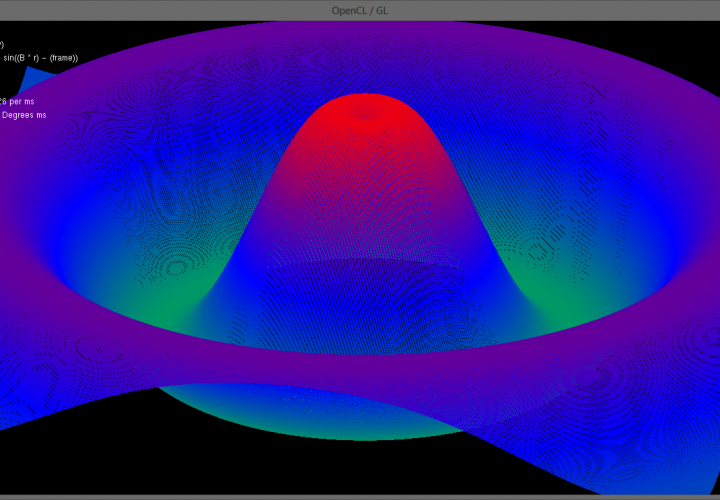
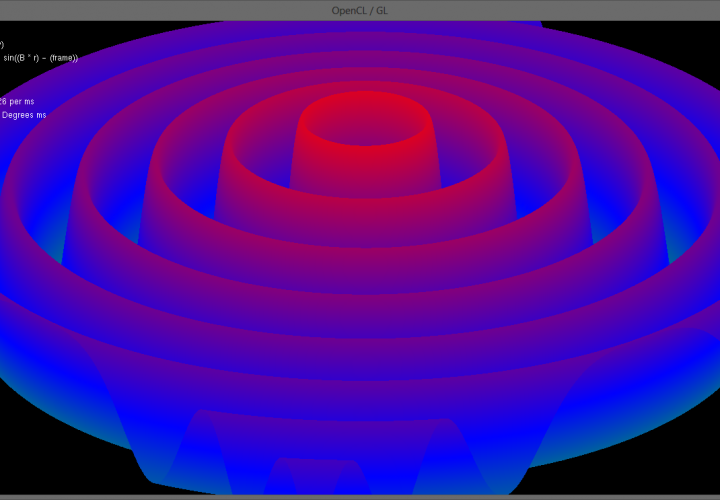
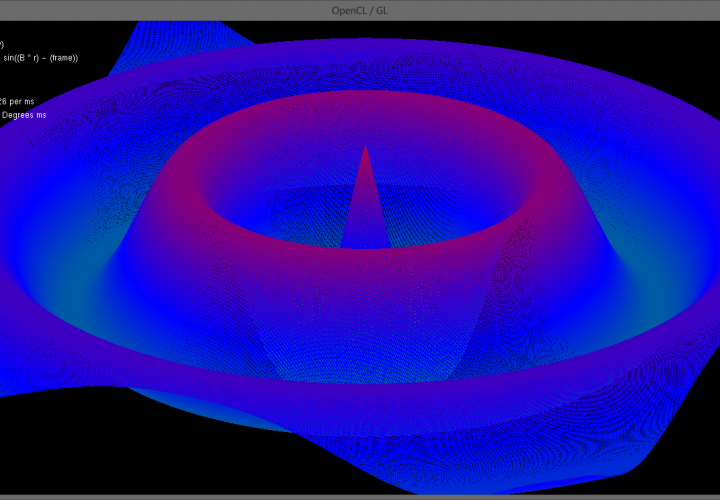
Using this frame as a base to build off of I was able to quickly and easily get a demo running. The program in the video above and the images below generates a 1000 * 1000 (1 million) vertex triangular mesh and displays an exponential sine function over it. At each frame OpenCL computes the 3D location of all 1,000,000 points in the mesh which OpenGL then renders. Due to the massively paralleled nature of the OpenCL update code frame rates exceeding 100 frames per second are achieved! (In the video Fraps capped the frame rate at 30fps for smooth capture)
Below is a simplified version of the SineMesh Demo, most of the work is performed in the initialization phase to create the 1000 * 1000 mesh and link the triangles together. The program could be made a lot more efficient if the triangle linking phase was done such that it creates a Triangle Strip as opposed to the current Triangle List. A strip has the benefit of chaining touching triangles together to save the number of vertices which need to be stored in the linking array.
Rejoice! For after one hell of a long year finally the dissertation is done dusted and thankfully handed in!
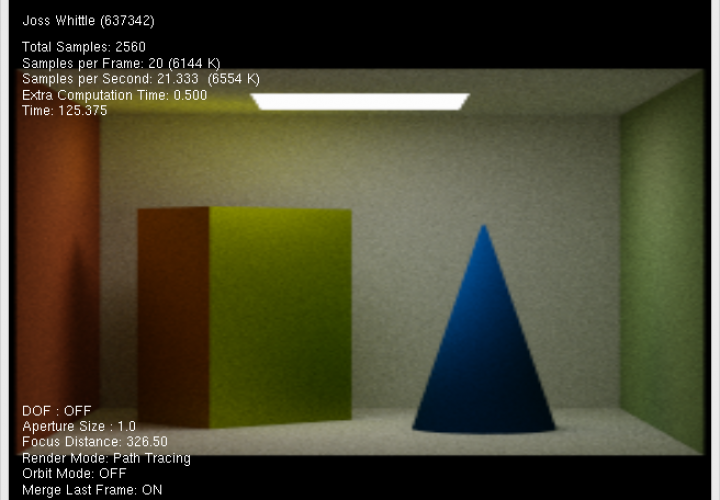
This was the final result, a real-time path tracer written in C using OpenCL to compute frames and OpenGl to render them. Here is a simple cornell box style scene that was left to converge for a couple of minutes.
My project fair demo. My graders seemed to like it (I bagged 92% for the Viva!) and so did the PhD students and my coursemates… Not so much praise from the school kids, the phrase “Realistic? Looks nothing like Call of Duty” was used…. First time I’ve ever wanted to smack a child jokes but what can you do. The tech industry people didn’t seem to care for it either which was rather miserable because I had to stand there for 5 hours in a boiling hot room while no one wanted to know about my work.
But I can’t really complain about not getting any job offers because… I got offered a summer research position unconditional fully funded PhD Studentship at the uni! So this summer I’ll be staying in Swansea to effectively continue this project with the goal of getting Path Tracing working much much faster and on mobile devices (tablets most likely).
Here’s an album showing the progress from start to finish throughout the year.
Thank goodness for that! After 4 solid weeks of exam revision, exams, getting my Dissertation Presentation done and actually going to this conference and presenting it I am finally free to relax and to sleep!!! (for 4 days until lectures start up again :/ )
I feel like I barely ever post on L2Program any more, not that too many people still read and I seldom check my analytics these days; but regardless, I wanted to post a quick update to show what I have been working on over the last month.
Below is an embedded version of my Presentation Slides that I used the other day. I was so nervous going into it, I usually visibly shake when I am on stage (and/or faint) but this time it went really well. I really do think what they say is true about presentations. That if it’s something you really care about and find interesting that you can present it much easier.
But no, this time I appeared to present my work quite well (if I do say so myself) and I bagged myself a 95 out of 100!
Anyway, here are the slides; they aren’t too bad (boring) to look at but possibly a bit out of context without my nerdy ramblings over the top of them.
Here are some larger versions of the screen shots from my demos. I was really excite to get to show how far my research had come since the beginning of the year and actually running live during the presentation seemed to be the best way of doing that. Once I’ve got a bit more work done I’ll post a video!
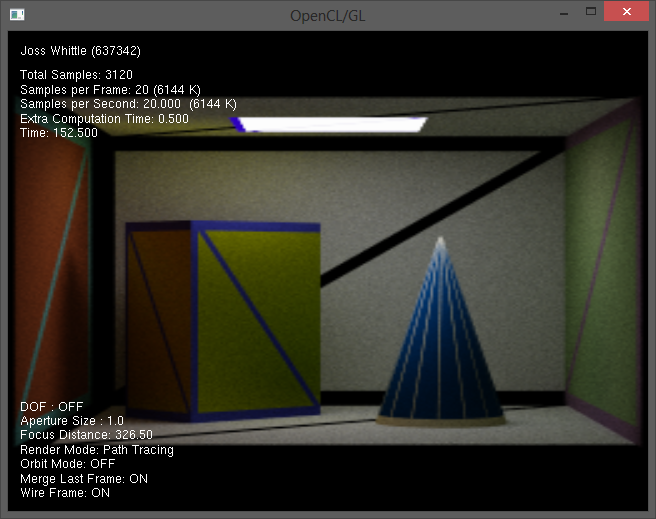
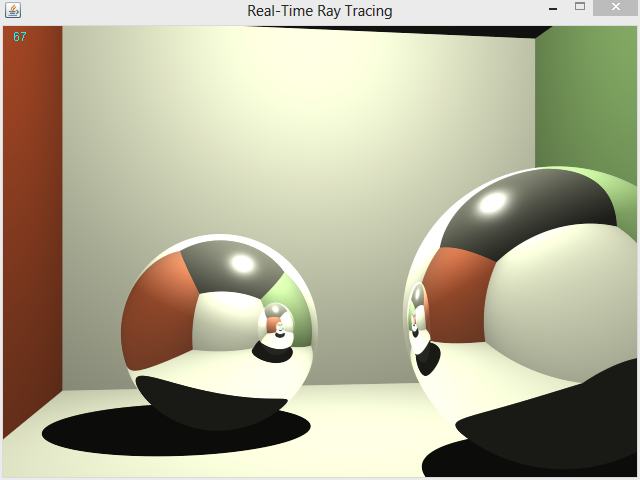
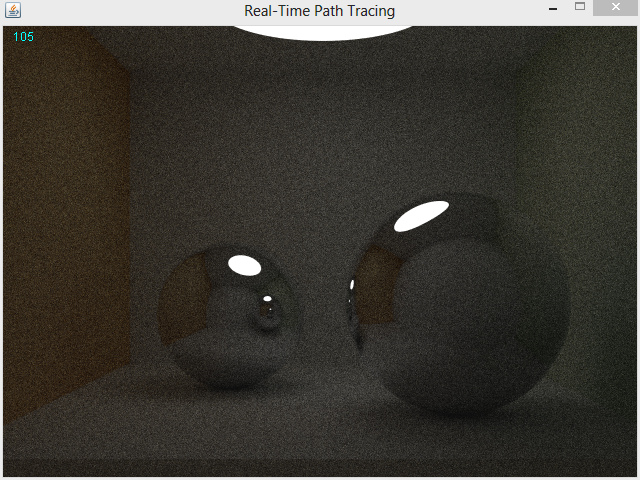
The camera can be controlled in real time using WASD for Slewing and Q & E for simple rotation. It’s entirely capable of looking up and down from a code standpoint I just ran out of time to get it ready and never mapped the up down to a key. The blue number in the top left is the number of samples computed; even though it is unnecessary to recompute the scene without a change in camera for Ray-Tracing I let it recompute anyway and jittered the exact location of the pixels by -0.5 < rand() <= 0.5 in X and Y to perform on the fly anti aliasing.
Real-Time Ray Tracing (20-30fps)
Real-Time Path Tracing (10fps’ish)
I had some problems with Path Termination using Monte-Carlo methods. Basically if one pixel returned almost immediately but the pixel next to it had to bounce 10+ times to compute it would crash the program (and the GPU :/ ) so to stop that happening during my demo I locked path termination to a simple MAX_DEPTH check. However, doing this meant the image on whole was a lot darker than it should be.