Hamiltonian Monte Carlo Simulations
February 10, 2014 - 5:41 pm by Joss Whittle Matlab PhD UniversityIt’s been a couple of weeks since I stopped working directly on rendering and took some time to read up on a topic called Hamiltonian (Hybrid) Monte Carlo which is to be the main focus of my research for the foreseeable future.
Hamiltonian Monte Carlo comes from a physics term of the same genesis called Hamiltonian Dynamics. The general idea being that, like with a Lagrangian equation for a system, you find a way to model the energy of a system which allows you to estimate it at efficiently even when the system is highly dimensional. With a Lagrangian you aim to minimize the degrees of freedom to reduce computation, and similarly with a Hamiltonian you reduce the problem to a measure of the systems kinetic K(p) and potential U(x) energy. This allows you to describe the entire state of an arbitrarily dimensional system as the sum of these measures, i.e. H(x,p) = U(x) + K(p)
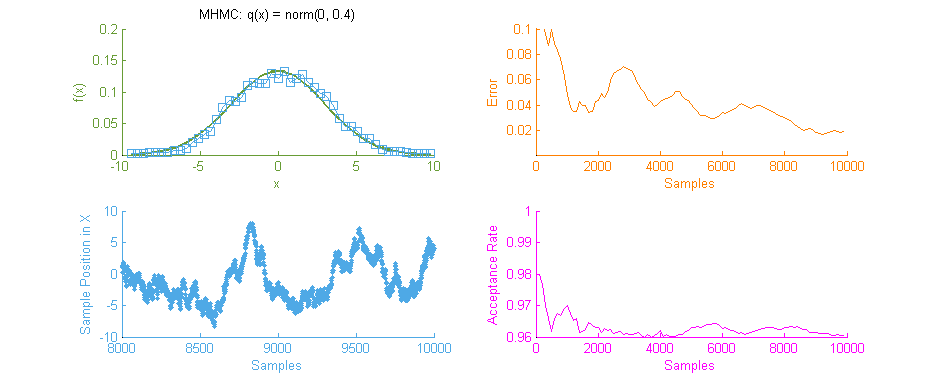
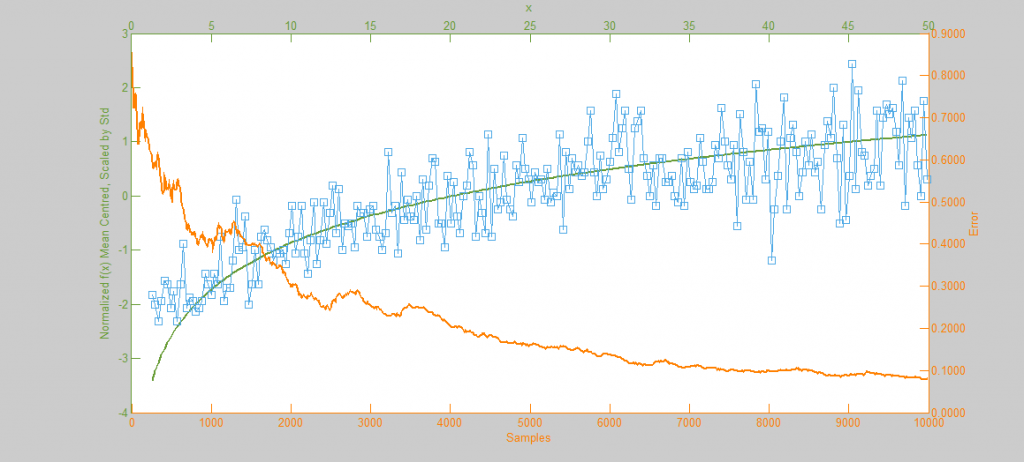
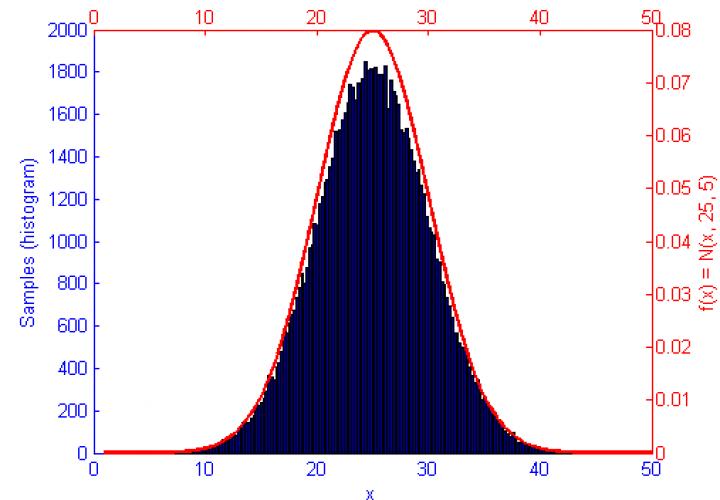
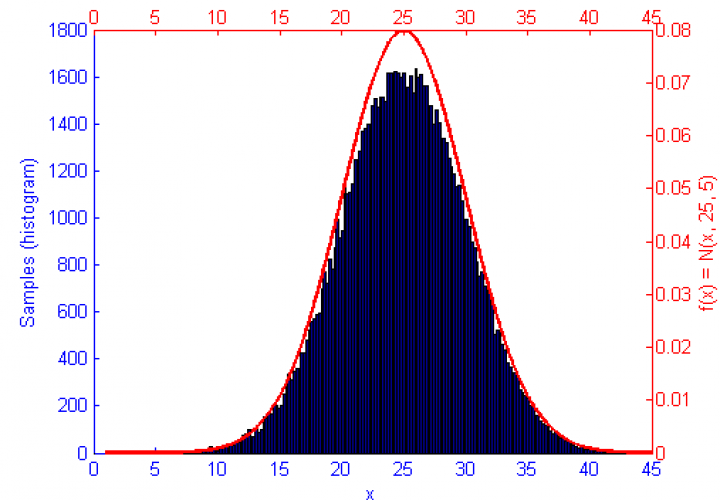
Above is our faithful companion, Metropolis Hastings Monte Carlo (MHMC), simulating a Normal distribution with mean “ and variance 3. The simulation was run for 10,000 samples yielding the shown results. Some things worth noting here are features such as the Error curve (Orange), which varies dramatically as simulation progresses. This is in-part due to the nature of the Random Walk which MHMC takes through the integration space which can be seen in the Blue graph to the bottom left. It is clear from the Blue graph that two states x and x' in the Makrov Chain are tightly dependent on one another.
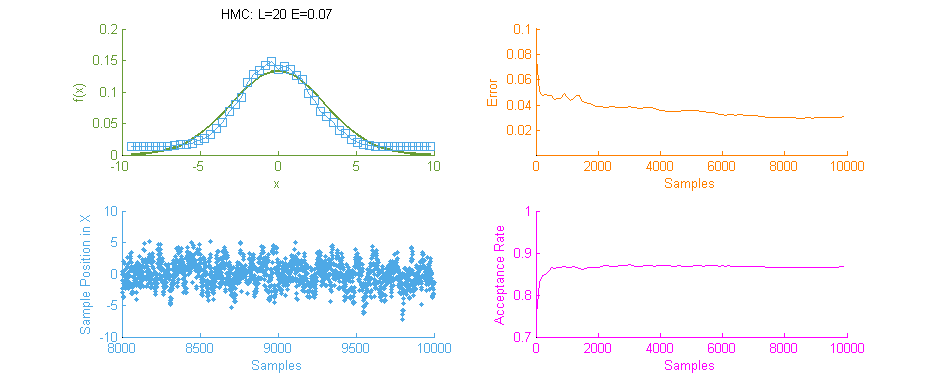
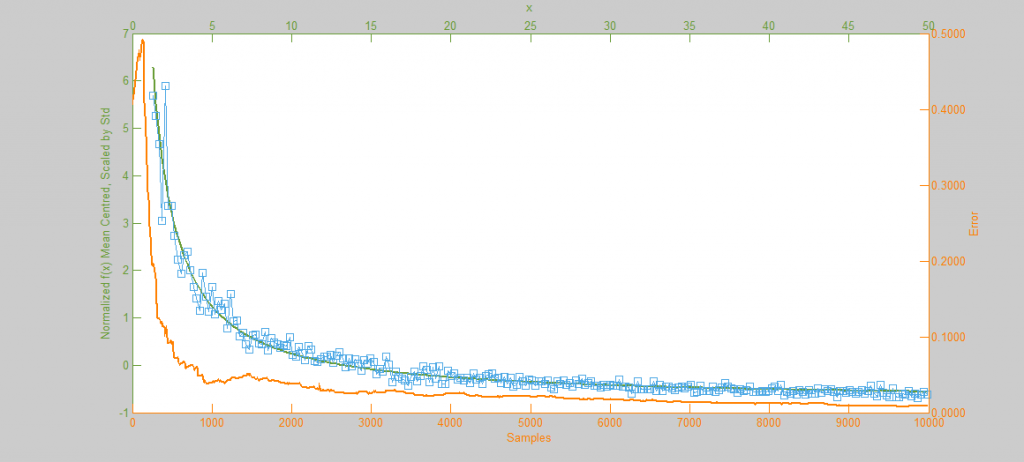
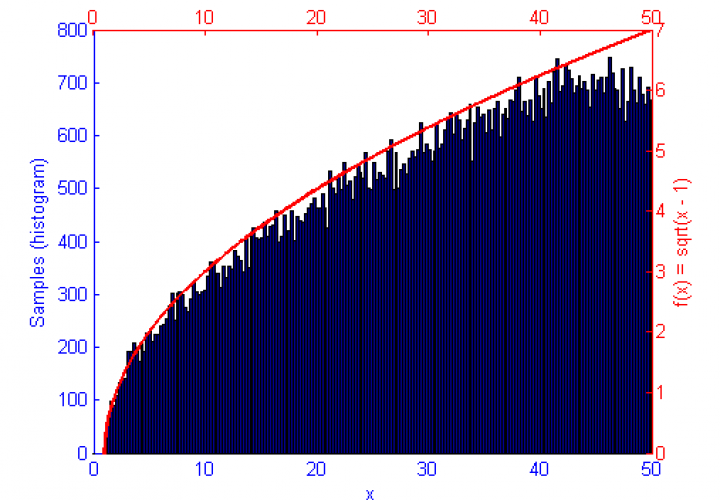
Next we see the same Normal distribution used above, estimated this time using Hamiltonian Monte Carlo (HMC) with trajectory length 20 and step size 0.07. To compare this to our previous simulation using MHMC several things become apparent. Firstly, The Error curve (Orange) seems to decay in a much more controlled and systematic manner. As opposed to the Error for MHMC which was erratic due to the nature of a Random Walk, here we see the benefit of making an informed choice as to where to place the next sample. From this we can hypothesise that a optimally tuned HMC simulation will in general reduce the error of the simulation with more samples consistently with little chance of introducing large, random, errors as with MHMC. Additionally in the sample placement graph (Blue) we see that the relationship between two states x and x' is far more abstracted, meaning two samples while being related and forming a valid Markov Chain will not reduce the accuracy of the simulation by treading on each others turf.
There is however, an issue with the above HMC simulation. Tuning. Unless properly tuned for the specific problem the Hyper-parameters for the Trajectory length L and Step size E will simply not work as intended and will yield poor results.
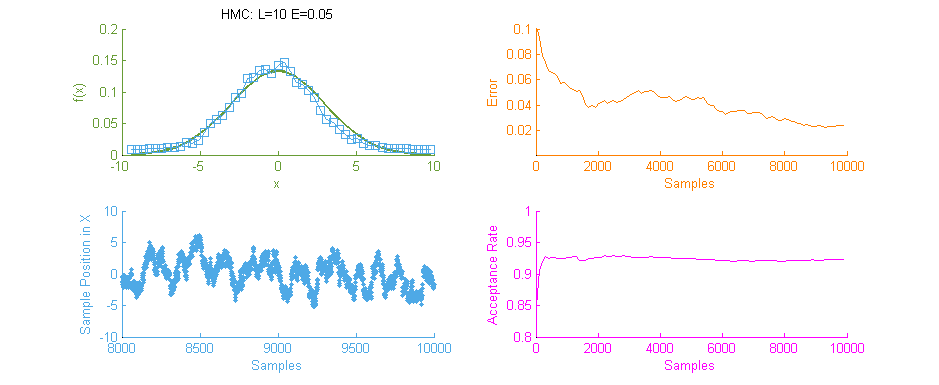
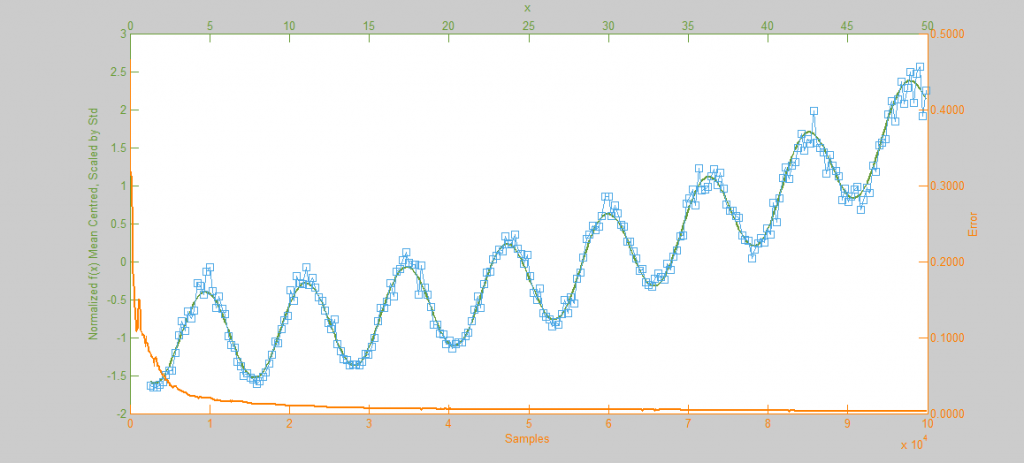
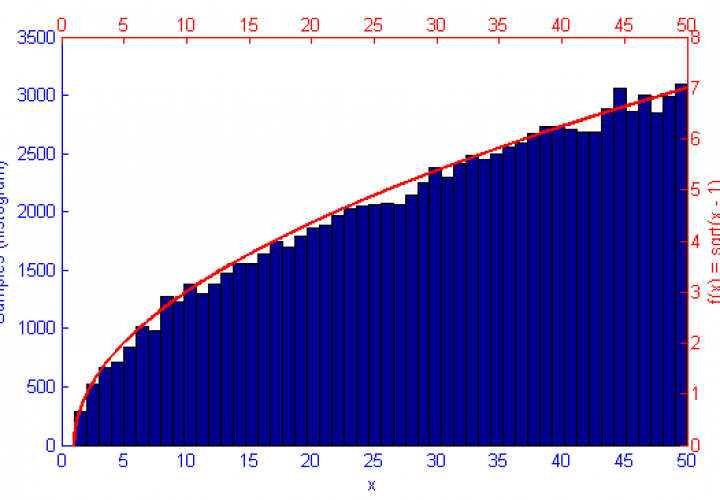
Above is a second run of the HMC simulation, this time with trajectory length 10 and step size 0.05. Because the length of the Leapfrog Trajectory was not sufficient to allow the system to move to an independent state we see the same banding of samples in the sample frequency graph (Blue) as we saw in the original Metropolis simulation. Additionally because of the dependent nature of the samples a similar pattern is seen in the Error curve (Orange) where the curve has large peaks where error was reintroduced to the system like with a Random Walk.
It is therefore vital to optimally tune HMC as the computation for each sample is an order of magnitude larger than with MHMC. Without proper tuning it’s much better to stick with the easier to tune MHMC.