Pressing onwards with research after a short break to play with the Xeon Phi rack, I’ve been working on visualizations for Monte Carlo Simulations.
My aim is to have a clean and concise means of displaying (and therefore being able to infer relationships from) the data of higher dimensional probability distributions. The video below shows one such visualization where a 2D Gaussian PDF has been simulated using Hamiltonian Dynamics.
Hamiltonian Dynamics Monte Carlo
The two 3D meshes represent the reconstructed sample volume as a 2D histogram of values rescaled to the original function. The error between the reconstruction and the original curves is shown through the colour of the surface where hot spots denote areas of high error.
The mean sq error for the whole distribution is displayed in the top right on a logarithmic scale. An algorithm which converges in an ideal manner will graph it’s error as a straight line on the log scale.
The sample X and Y graphs in the bottom right allow us to visualize where the samples are being chosen as the simulation runs and infer about whether samples are being chosen independently of one another. The centre-bottom graph simply gives us a trajectory of samples over the course of the simulation. This allows us to additionally catch if an algorithm is prone to getting stuck in local maxima’s.
Metropolis Hastings Monte Carlo
The above video shows the same simulation run with a basic Metropolis Hastings algorithm. Here the proposal sample x and y attributes are chosen independently of one another, meaning this is not a Gibbs Sampler. Although I intend to implement one within the test framework for comparisons sake soon.
A key difference between the two simulations here is to note the Path Space Trajectory shown in the bottom-centre graph and how it relates to the Sample Dimension Space graphs shown on the middle & bottom-right. Hamiltonian Dynamics chooses sets of variables where the x and y elements are highly dependent on one another within a coordinate, yet almost entirely independent of other pairs of coordinates within the Path Space.
Metropolis Hastings on the other hand, chooses coordinate pairs entirely independently of one another, and values within each dimension of the Path Space that are highly dependent on one another. These characteristics of the Metropolis sampler are undesirable, which is why adding a dependency within coordinate pairs (Gibbs Sampling) helps to accelerate multi-dimensional Metropolis Samplers.
It’s been a couple of weeks since I stopped working directly on rendering and took some time to read up on a topic called Hamiltonian (Hybrid) Monte Carlo which is to be the main focus of my research for the foreseeable future.
Hamiltonian Monte Carlo comes from a physics term of the same genesis called Hamiltonian Dynamics. The general idea being that, like with a Lagrangian equation for a system, you find a way to model the energy of a system which allows you to estimate it at efficiently even when the system is highly dimensional. With a Lagrangian you aim to minimize the degrees of freedom to reduce computation, and similarly with a Hamiltonian you reduce the problem to a measure of the systems kinetic K(p) and potential U(x) energy. This allows you to describe the entire state of an arbitrarily dimensional system as the sum of these measures, i.e. H(x,p) = U(x) + K(p)
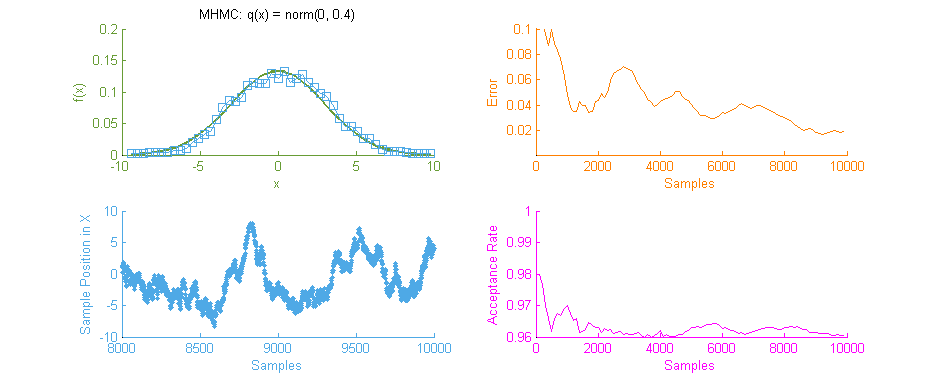
Above is our faithful companion, Metropolis Hastings Monte Carlo (MHMC), simulating a Normal distribution with mean “ and variance 3. The simulation was run for 10,000 samples yielding the shown results. Some things worth noting here are features such as the Error curve (Orange), which varies dramatically as simulation progresses. This is in-part due to the nature of the Random Walk which MHMC takes through the integration space which can be seen in the Blue graph to the bottom left. It is clear from the Blue graph that two states x and x' in the Makrov Chain are tightly dependent on one another.
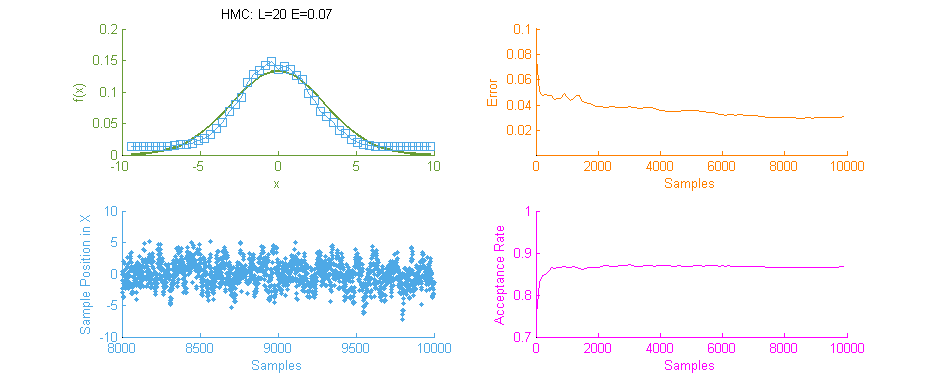
Next we see the same Normal distribution used above, estimated this time using Hamiltonian Monte Carlo (HMC) with trajectory length 20 and step size 0.07. To compare this to our previous simulation using MHMC several things become apparent. Firstly, The Error curve (Orange) seems to decay in a much more controlled and systematic manner. As opposed to the Error for MHMC which was erratic due to the nature of a Random Walk, here we see the benefit of making an informed choice as to where to place the next sample. From this we can hypothesise that a optimally tuned HMC simulation will in general reduce the error of the simulation with more samples consistently with little chance of introducing large, random, errors as with MHMC. Additionally in the sample placement graph (Blue) we see that the relationship between two states x and x' is far more abstracted, meaning two samples while being related and forming a valid Markov Chain will not reduce the accuracy of the simulation by treading on each others turf.
There is however, an issue with the above HMC simulation. Tuning. Unless properly tuned for the specific problem the Hyper-parameters for the Trajectory length L and Step size E will simply not work as intended and will yield poor results.
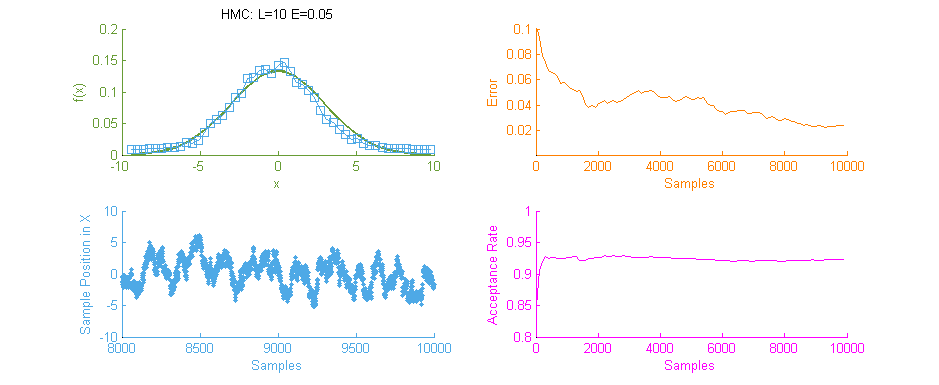
Above is a second run of the HMC simulation, this time with trajectory length 10 and step size 0.05. Because the length of the Leapfrog Trajectory was not sufficient to allow the system to move to an independent state we see the same banding of samples in the sample frequency graph (Blue) as we saw in the original Metropolis simulation. Additionally because of the dependent nature of the samples a similar pattern is seen in the Error curve (Orange) where the curve has large peaks where error was reintroduced to the system like with a Random Walk.
It is therefore vital to optimally tune HMC as the computation for each sample is an order of magnitude larger than with MHMC. Without proper tuning it’s much better to stick with the easier to tune MHMC.
Continuing on from experiments last week with Metropolis Hastings sampling for probability distributions I decided to implement Accept-Reject sampling. Accept-Reject seems to deliver well distributed results faster than Metropolis Hastings does but in the long run can easily introduce biased samples if the proposal distribution q(x) is not well tuned to the specific probability distribution function. MH on the other hand, is far more resilient to an improperly chosen proposal distribution as it will still converge to an unbiased result in most cases, albeit by taking a longer time to converge than it normally would. Accept-Reject also seems to have issues towards the truncations of it’s function causing under-sampling of values close to the lower and upper bounds.
A little update on what I’ve been learning about lately.
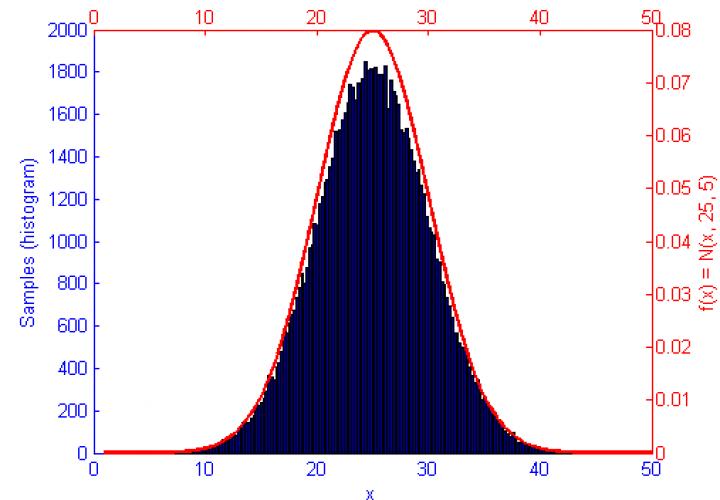
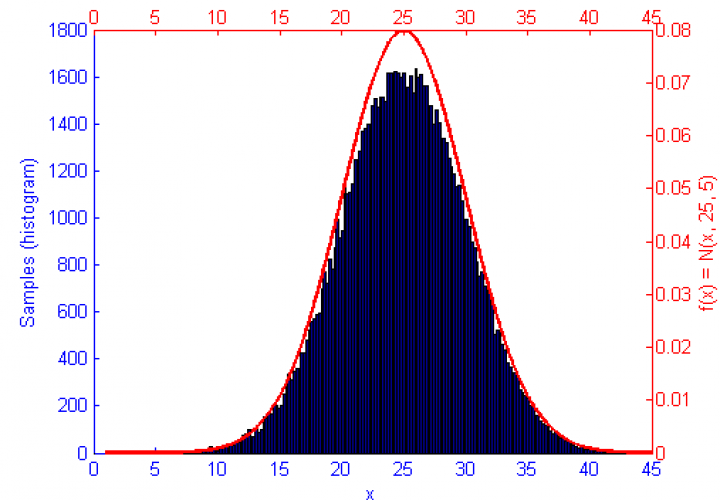
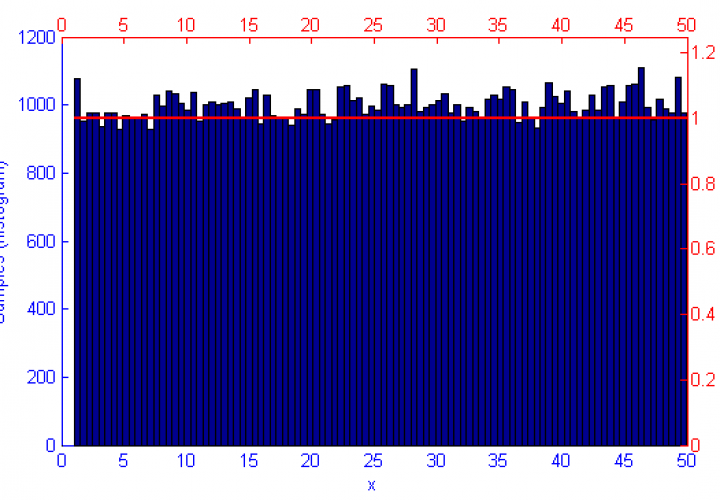
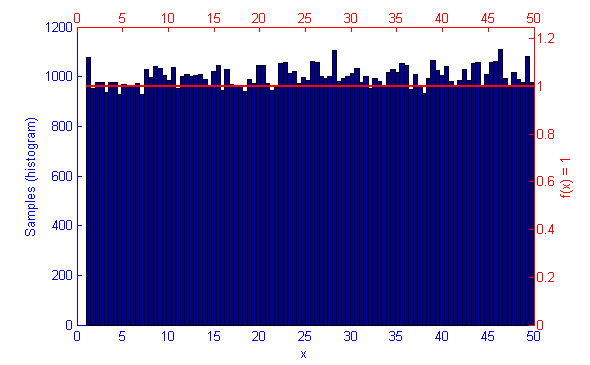
Metropolis-Hastings is an algorithm for sampling random values out of a probability distribution. Effectively, for a function f(x) you wish to simulate where the curve is higher it is more probable that a random number will be chosen from there. Uniform sampling of the range would mean that all x values on the graph have an even probability of being chosen, this could be simulated by saying f(x) = 1.
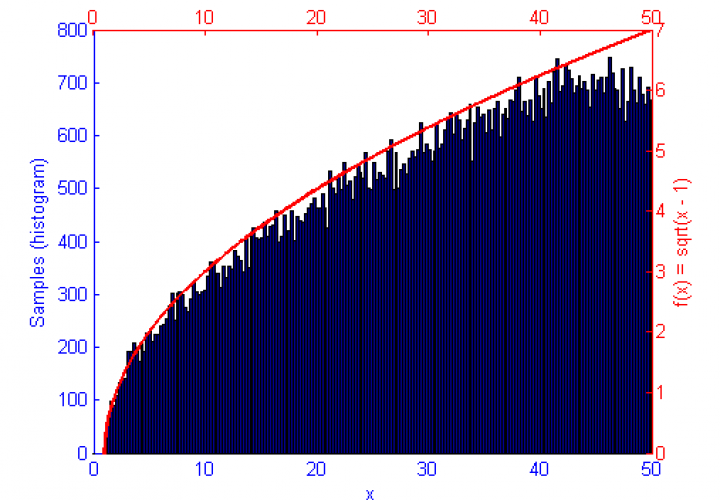
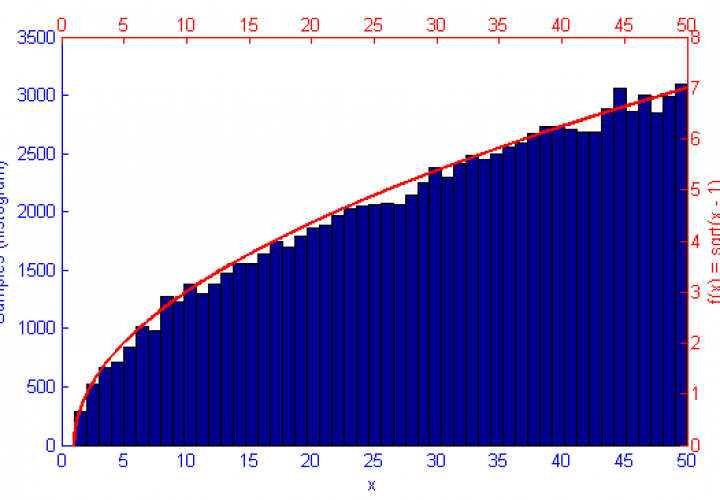
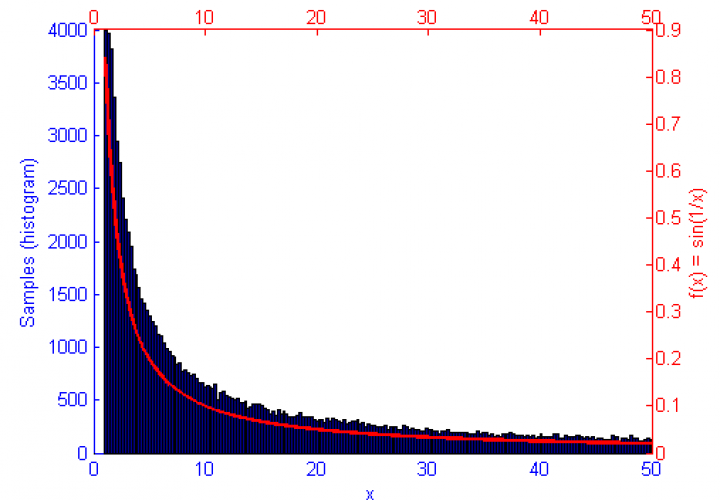
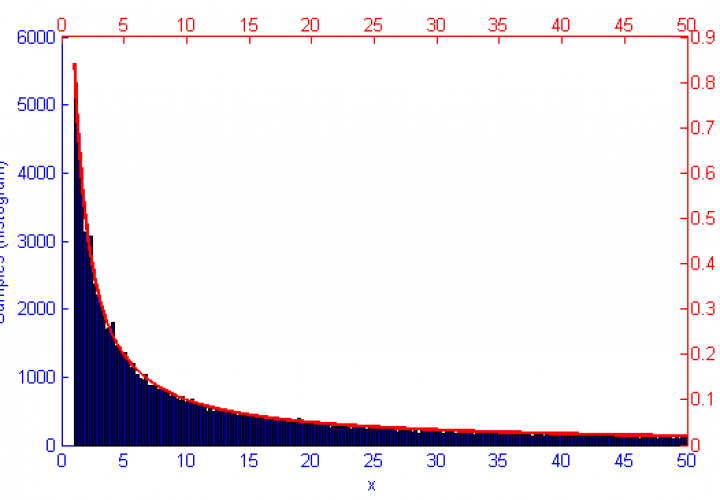
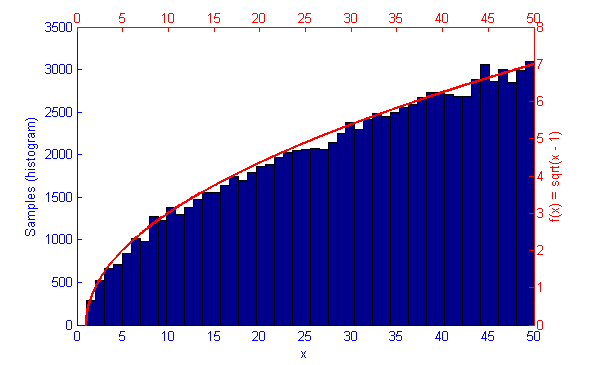
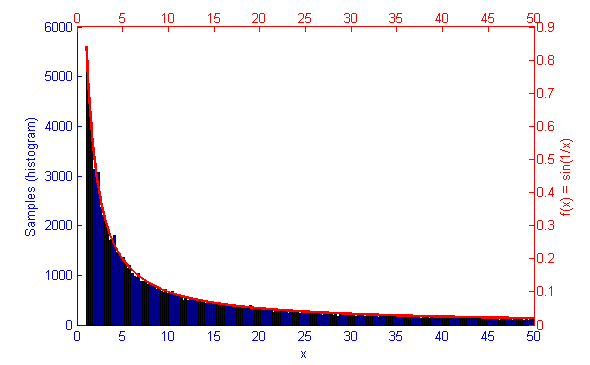
However, if the function f(x) represents a curve then the number of samples in high energy (probability) regions needs to be more dense. This can be seen in the simulations of f(x) = sqrt(x-1) and f(x) = sin(1/x) below.
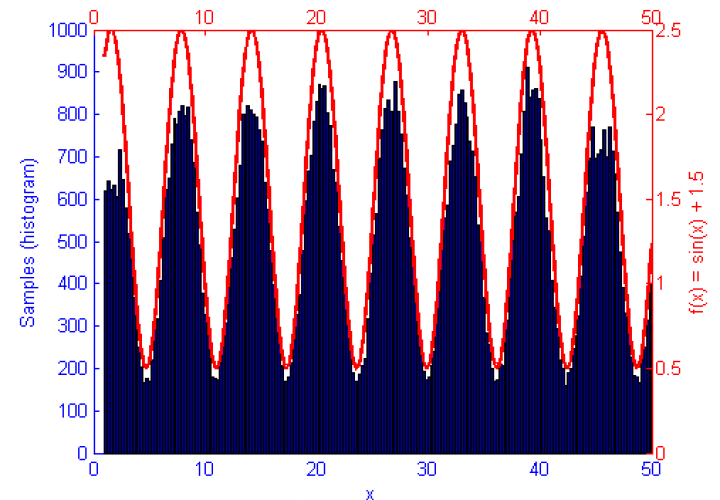
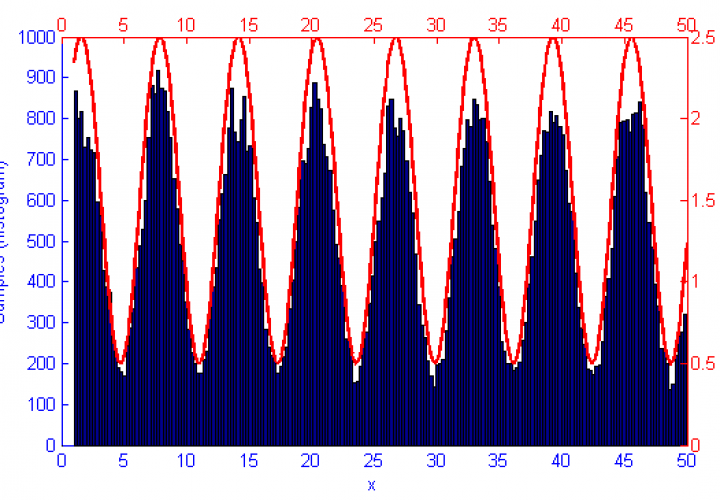
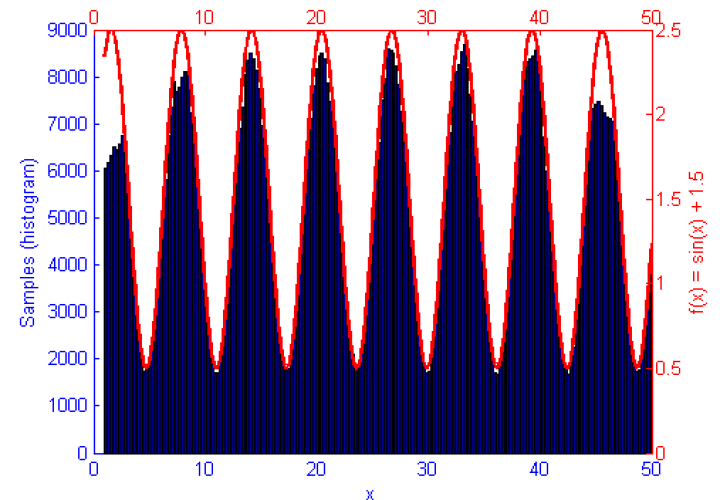
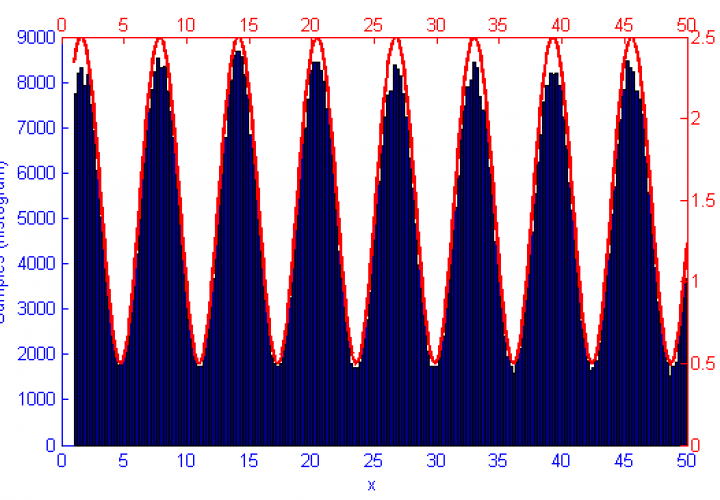
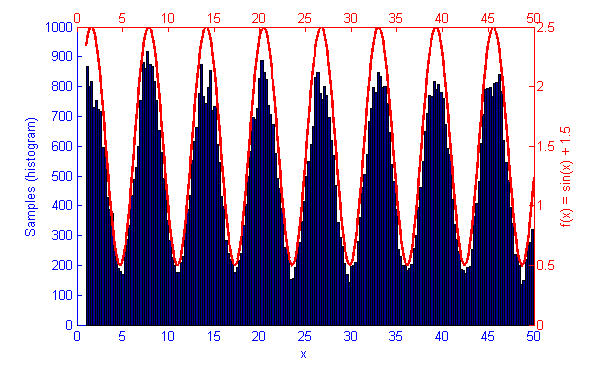
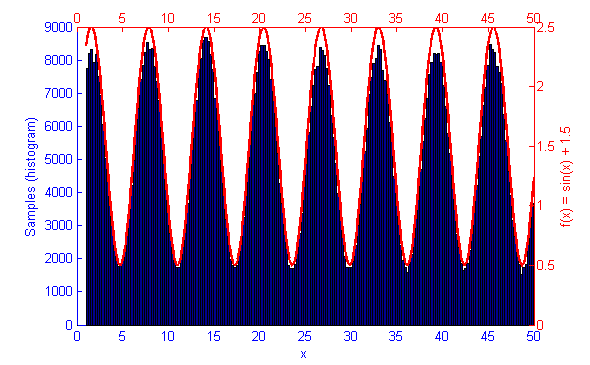
Metropolis-Hastings is best suited to problems where Direct Sampling and other more efficient solutions are not available. Because it only relies on the availability of a computable function f(x) and a proposal density Q(x|x*) M-H can correctly sample unusual probability distributions that would else-wise be difficult or impossible to compute. This can be seen below in the simulations of the sine function f(x) = sin(x) + 1.5.
Matlab code for Metropolis-Hastings Monte Carlo Integration (for generating samples)
Below is the Matlab code used to generate the above graph. By modifying the function f(x), the sample count N, the proposal distribution and it’s variance qV, and the upper and lower truncation bounds LB & HB any PDF can be simulated.
Work continues and it’s going well! Over the last week I have been teaching myself Bayesian Statistics which allows you to think about probability in terms of degrees of belief. It is also predicated on the concept of parameters, or prior known data, allowing you to update the probability of something happening in the future. This allows for convergent solutions on unknown probabilities which useful in graphics in terms of being able to fully sample arbitrary probability distributions.